

Content
- Overcoming the Data Availability Problem
- Congestion, Rollups and Blockspace
- The Web’s Paradigm Shift from Servers to Clouds
- Monolithic Blockchains: One Server Per Network
- A Pluggable Consensus & Data Availability Layer: The Cloud of Blockchains
- Overcoming Data Availability Costs: Data Availability Sampling
- Erasure Coding
- Data Availability Sampling (DAS)
- How Celestia Achieves Its Purpose
- Querying Storage Nodes
- Utilising Namespaced Merkle Trees
- Safeguarding Against Incorrectly Ordered Merkle Trees
- Verifying Merkle Proofs
- A Summary of the Problems Celestia is Conquering & How
- The Synergy Between Rollups and Celestia
- The Future Applications of Celestia
- Sovereign Rollups
- Hosting Additional Virtual Machines
- Celestiums
- Protecting Rollups from Distributed Denial of Service (DDoS) Attacks
- Cevmos: Settlement Layer for Rollups
- Conclusion
- About Zerocap
- FAQs
- What is the main problem that Celestia aims to solve in the blockchain space?
- How does Celestia's architecture differ from traditional blockchains?
- What is Data Availability Sampling (DAS) and how does Celestia use it?
- What is erasure coding and how does it contribute to Celestia's approach?
- How does Celestia's approach contribute to the future of blockchain technology?
- DISCLAIMER
1 Aug, 23
Blockchain’s Evolution From Individual Servers to a Shared Cloud: Celestia

- Overcoming the Data Availability Problem
- Congestion, Rollups and Blockspace
- The Web’s Paradigm Shift from Servers to Clouds
- Monolithic Blockchains: One Server Per Network
- A Pluggable Consensus & Data Availability Layer: The Cloud of Blockchains
- Overcoming Data Availability Costs: Data Availability Sampling
- Erasure Coding
- Data Availability Sampling (DAS)
- How Celestia Achieves Its Purpose
- Querying Storage Nodes
- Utilising Namespaced Merkle Trees
- Safeguarding Against Incorrectly Ordered Merkle Trees
- Verifying Merkle Proofs
- A Summary of the Problems Celestia is Conquering & How
- The Synergy Between Rollups and Celestia
- The Future Applications of Celestia
- Sovereign Rollups
- Hosting Additional Virtual Machines
- Celestiums
- Protecting Rollups from Distributed Denial of Service (DDoS) Attacks
- Cevmos: Settlement Layer for Rollups
- Conclusion
- About Zerocap
- FAQs
- What is the main problem that Celestia aims to solve in the blockchain space?
- How does Celestia's architecture differ from traditional blockchains?
- What is Data Availability Sampling (DAS) and how does Celestia use it?
- What is erasure coding and how does it contribute to Celestia's approach?
- How does Celestia's approach contribute to the future of blockchain technology?
- DISCLAIMER
As a nascent industry, the blockchain space is in a constant state of evolution. With respect to the human species, the catalyst for evolution was and remains to be the need to survive. On a parallel, the catalyst for the evolution in the blockchain world is the exorbitant cost of gas. Accordingly, the scale that blockchain evolution focuses on is scaling networks to support high quantities of transactions without forcing users to face costly gas fees. The most popular approach to evolving, that is, scaling blockchains, is one that is modular; each specific functionality of the blockchain is achieved by an individual network. Celestia is one such network that takes ownership over key purposes of blockchains – data availability and consensus. This article will explore the Celestia network and its current success in scaling blockchains.

Overcoming the Data Availability Problem
At a fundamental level, whilst traditional blockchains like Bitcoin and Ethereum facilitate simple and sophisticated movements of transactions, they further serve the purpose of a data platform that leverages decentralised storage methods. Each block in the longest chains of linked blocks is bits of data that represents transactions and transaction movements that occurred within that period of time. Accordingly, data availability in blockchains ensures a proposed block has complete transaction data accessible to all network participants; this is vital for maintaining blockchain integrity, trust, and confirming transaction validity. This data is a part of each block and is crucial for the operation of decentralised networks; a historical and immutable ledger. Accordingly, data availability represents the promise of accessibility of data within the blockchains – the guarantee that every transaction ever facilitated on the chain can be accessed by all network participants.
This forms the idea of social consensus based on agreed-upon truths. To ingrain these truths into the walls of the blockchain itself, a block disseminated throughout the network’s nodes must ensure that all data contained relating to transactions included in a block are available to be downloaded. Notably, within each block is a data limit, emblematic of its storage limit – this concept is known as blockspace. As the data within the block is distributed to other network participants, certain nodes, known as full nodes, download and re-execute the transactions. This process enables the validity of every transaction in the proposed block to be confirmed and consequently results in the illumination of malicious transactions included by the block builder.
In this sense, traditional blockchains, like Bitcoin and Ethereum, rely on individuals, entities and companies to run full nodes to protect the security and functionality of the network. However, running a node that is constantly performing these tasks is computationally challenging and requires storage space and an intensive supply of processing power. Subsequently, the full nodes that are tasked with verifying the integrity of the blockchain by checking that the blocks and transactions conform to the network’s consensus rules, cannot be run by most individuals.
Responding to the foundational difficulty in securing the network and increasing its decentralisation, many participants were encouraged to host light nodes. Also known as light clients, light nodes do not store the full copy of the network, but instead rely on simple proofs and a trust-based relationship with full nodes to validate transactions. Light nodes do not download the full block, rather are designed to accept the header of the block, which is signed off on by a majority of validators or miners. This approach to overwhelming node requirements proved effective as whilst they provide a lower level of security and decentralisation to a blockchain, they are convenient for a broader geographic of network participants.
Notwithstanding, as well as these description differences, full nodes and light nodes are crucially independent in another important way; light nodes are not capable of meeting the stringent requirements of the data availability guarantee. As such, the existence, presence and impact of light nodes unintentionally gave rise to the data availability problem. Full nodes have access to the entire block and hence cannot submit proofs to light nodes relating to a block’s validity or invalidity due to the inherent reliance that the recipient has access to all of the blockchain’s data. Herein lies the problem; light nodes rely entirely on the trustworthiness of full nodes within the network.
The data availability problem is indicative of this reliance on full nodes. It arises when developers strive to build and design trust-minimised light clients that have access to all data in a block. This way, the client will not be reliant on the full nodes for their transaction data and accordingly can operate independently as opposed to a delegate model. Concurrent with this feature, the operation and upkeep work to guarantee liveliness, for the light node cannot increase to the extent that it can be compared to a full node.
Celestia focuses on this problem with a modular alternative establishment approach for light clients.
Congestion, Rollups and Blockspace
Whilst this problem and the dire need for a solution to trustless light nodes are clearly relevant, a question could emerge over whether the sickness presently necessitates a remedy.
One commonly preached statement in the blockchain space goes along the lines of “we are ready to onboard the next million users” of the technology. Yet, this perspective is indicative of builders’ dereliction of their duty of focusing on the current million users that face friction frequently when transacting. Throughout 2021 and 2022, gas fees for the Ethereum network skyrocketed to previously unseen heights. Like all markets, the amount of gas paid per transaction floats based on demand and supply. As expected, demand is symbolic of the volume of individuals or entities seeking to transact at any specific time; for a short-lived opportunity such as arbitrage, gas will mushroom as demand eclipses the supply.
The supply, on the other hand, is determined by limitations on data in each block. Using gas as the general resource to measure the cost of a single transaction in a block, following EIP-1559, Ethereum blocks have a variable long-term average gas target of 15 million gas. This means that gas will rapidly increase to manage block sizes once the weight of all transactions in a single block exceeds the 15 million gas target. Further to this, each Ethereum block is still hard-capped at 30 million gas units. More details on how gas is calculated and this target is maintained can be found in Zerocap’s article on the London hard fork and introduction of EIP-1559.
Moreover, giving additional depth to the significance of this issue of congestion, the Ethereum roadmap, fundamentally concentrates on making the base layer the optimal consensus and data availability chain for layer 2 networks operating atop the blockchain. Rollups and other layer 2 scaling solutions seek to improve the user experience for layer 1 networks, like Ethereum, by lowering transaction costs and execution speeds. In the case of rollups, this is achieved through batching a substantial number of transactions together into a rollup and posting that compressed transaction onto the base layer (typically Ethereum). This method allows all transactors in a unique batch to share the single transaction cost on Ethereum.
Yet, like most software-based solutions for scalability, when battle-tested another issue emerged within the existing remedy. As smart contracts on layer 2s get more complex, increasingly more data related to the execution of the contract is posted onto the layer 1. Given the importance of the data guarantee for blockchains, all of this data, known as calldata, must be accessible for nodes validating the transactions on the layer 1. Without the calldata, the batch of transactions is unable to be validated and further, if it is not stored in a block’s data, data availability cannot be guaranteed. Therefore, while it may appear that rollups are effectively elevating a blockchain ecosystem’s transactional output, costs asymmetrically rise with respect to data availability.
Subsequently, blockchains are becoming severely congested, with this pressure falling directly onto the full node providers without the ability to leverage the support of trust-minimised light nodes.
The Web’s Paradigm Shift from Servers to Clouds
Individuals within the space, typically those referred to as “grifters”, enjoy frequently analogising the growth and adoption of the blockchain space to that of the internet. Be that as it may, a more appropriate and accurate comparison to make is the evolution of the technology underpinning both industries.
Not all products and services that have emerged out of the connectivity provided by centrally organised servers and clouds were as aesthetically easing and convenient to use. Instead, in the early days of the web, each website would need to manage and run its own physical server. The overhead of this task likely deterred many individuals and companies from leveraging the burgeoning technology. Gradually, an innovative solution emerged to advance the state of the technology – shared hosting providers; resultantly, setting up a website became substantially more convenient without the necessity for a physical server. Through the passage of time, the creation of cloud-based storage systems, each website was able to host its own virtual machine to herald new heights of flexibility and control through unparalleled modularity without drastically raising costs.
The evolution of the computer industry can be valued through the lens of the progression of cells from single-celled organisms to complex multicellular organisms. Before the advent of SDKs and cloud computing, each computer was like a single-celled organism, having to store all its information within its own limited boundaries. However, following the introduction of these technologies, computers have evolved into multicellular organisms, where information can be stored in a shared “cloud server” like a central nervous system, allowing for greater storage capacity and interconnectivity.
As blockchains begin to face scalability and cost-related issues that are fundamentally akin to those experienced by internet systems, solutions applied to decentralised networks can be distilled and compared to the evolution of alternative, centralised servers. Prior to general-purpose blockchains like Ethereum, decentralised networks were only able to facilitate a single utility, built into its very infrastructure. For example, the miners for the Bitcoin blockchain supported the network’s goal of facilitating a decentralised, trustless payment system. Nonetheless, with the establishment of The World Computer, Ethereum, a Turing-Complete blockchain, new utilities could be achieved without dogmatically requiring its own validator set; instead, it could rely on the Ethereum validator. Although this represented a substantial leap from the single-purposed Bitcoin to a standard of smart-contract-enabled blockchain, each general-purpose blockchain undertook each role of a network; consensus, execution, settlement and data availability.
Brought upon by the dawn of layer 2 scaling solutions that solely strive to act as an execution network for blockchains, decentralised networks have begun to modularise themselves.
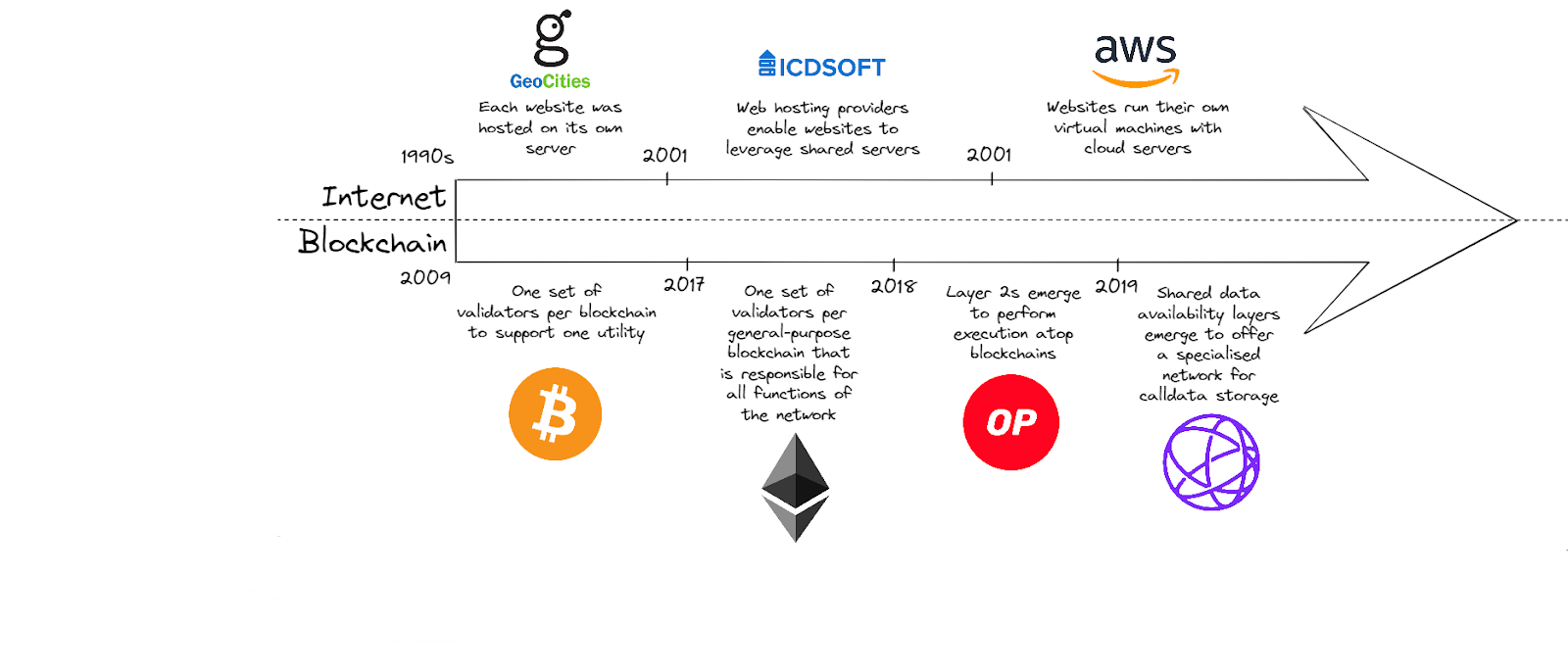
Monolithic Blockchains: One Server Per Network
As introduced in the prior section, blockchains are only starting to delegate the many roles which they are required to perform. As such, the current state of existing blockchains is still relatively monolithic and insular, typically operating in a vacuum without leveraging the services of other chains. This can best be visualised with Ethereum; the Ethereum Network provides the consensus mechanism to validate transactions, execution for smart contracts via the Ethereum Virtual Machine (EVM), blocks to store transactional data and settlement mechanisms for proofs. Whilst this is positive in providing a shared execution environment for decentralised applications (dApps) on Ethereum, it results in all Ethereum-based contracts being bound by the same rules which are compatible with the EVM.
The monolithic architecture of these chains is severely limiting and gives rise to congestion as well as the corresponding problems faced by users of such blockchains. Monolithic blockchains seek to generalise the roles, offering a distributed and decentralised ledger for transactions, holdings, data storage, settling proofs and more. In the case that one role is more computationally expensive than the other due to this uniform design, on-chain transactors bear this pain in the form of additional costs.
Shifting to focus specifically on the data side, it becomes clear that blockchains utilise their execution environment for storing data as blocks become primarily filled with calldata instead of transactions. This is an initial similarity between the early stages of the internet and blockchains; one native, sovereign server per website, or in this case, blockchain. However, once again, akin to the shared cloud systems offered to websites, specialised blockchains, like Celestia, have emerged that offer chains a single network to store transaction data and blocks. In this way, blockchains are not finding themselves levying additional costs on transactors who are required to pay for the data availability guarantee, but rather offering substantially cheaper costs.
A Pluggable Consensus & Data Availability Layer: The Cloud of Blockchains
Celestia is an innovative force in the blockchain landscape, meticulously engineered to serve as a pluggable consensus and data availability layer for other blockchains, with a primary focus on rollups. As the cloud of blockchains, Celestia is capable of decoupling consensus and execution, akin to separating the conductor from the orchestra, which enables a more efficient and harmonious performance. Within this framework, consensus is achieved through the utilisation of the Tendermint consensus protocol, while the data availability guarantee is maintained. This ensures that all transactions in a block are available and posted by the block proposer, empowering the network to determine the state of the blockchain.
Celestia’s key innovation lies in the distinct separation of transaction ordering and validation. Instead of validating transactions, Celestia relies on a thin core layer to order transactions, while the execution layer of the modular blockchain stack is responsible for validation. By doing so, it reduces complexity and enhances the overall efficiency of the system. As outlined in the paper “LazyLedger: A Distributed Data Availability Ledger With Client-Side Smart Contracts,” Celestia’s core layer solely focuses on data availability, ensuring that all data is accessible to clients who can then independently validate the transactions.
This unique approach allows rollup nodes, operating under the same validity rules, to compute the same state as long as Celestia’s history remains unaltered. By offloading the validation process to the execution layer, Celestia significantly reduces the resource requirements on the network, leading to increased scalability and security. Furthermore, it allows for a higher degree of flexibility, as different execution environments can be easily plugged into Celestia, thereby fostering an ecosystem of diverse and customizable solutions.
Celestia’s groundbreaking architecture liberates rollups from the necessity of depending on another blockchain for execution to share security. It achieves this by ensuring that all that is required is an agreement on a shared history of ordered transactions. This innovative approach effectively transforms Celestia into a “data availability oracle” that efficiently verifies the availability of data, ensuring that even if a block proposer had to behave maliciously, the system would still maintain its security and functionality. Hence, by decoupling consensus and execution, Celestia paves the way for a more modular blockchain ecosystem, enabling various projects to leverage its data availability guarantees without being confined by a single execution environment. Consequently, this framework offers a scalable and secure foundation for the future of blockchain technology, accommodating a wide array of applications and protocols that can seamlessly integrate with Celestia to achieve unparalleled levels of efficiency and security.
Overcoming Data Availability Costs: Data Availability Sampling
Data Availability Sampling (DAS) serves as a cornerstone in Celestia’s innovative approach to achieving data availability while maintaining scalability. By not requiring every participant to download and validate the entirety of the data, DAS introduces a more efficient and cost-effective method to ensure data availability. The magic behind DAS lies in erasure coding, a redundancy technology with origins in physical media such as CD-ROMs. Erasure coding adds extra redundant data to the original data, enabling recovery even in cases of corruption or loss. This is achieved by transforming the original data into a polynomial, using the coefficients to generate redundant data points. The encoded symbols are chosen in such a way that the polynomial can be reconstructed from a sufficient number of them, even if some are lost or corrupted.
Celestia’s DAS implementation takes advantage of erasure coding, further explained below, enabling blocks to be validated in sub-linear time due to widespread participation. Instead of relying on each validator to store an entire block’s worth of transactions before validating it, DAS allows validators to perform smaller tasks, ultimately leading to smaller fees. This approach also prevents bots from spamming the network, as fees act as a deterrent.
In Celestia’s network, the block size increases based on the number of validators, maintaining a probability of block restoration greater than 99%. As a result, all participants continue to sample the same amount of data, but the increased number of validators allows for an increase in block size without losing the required probability bound. This ingenious method facilitates horizontal scaling, ensuring both data availability and network scalability.
Erasure Coding
Erasure coding, a meticulously crafted technique, weaves an intricate web of redundant data that protects the original piece. Its primary goal: to recover the data despite corruption or loss. Erasure coding’s magic emerges from the mathematical realm of polynomial interpolation, where a polynomial is constructed to pass through a set of data points. By using this polynomial, extra redundant data melds with the original data, poised to repair any errors or missing information.
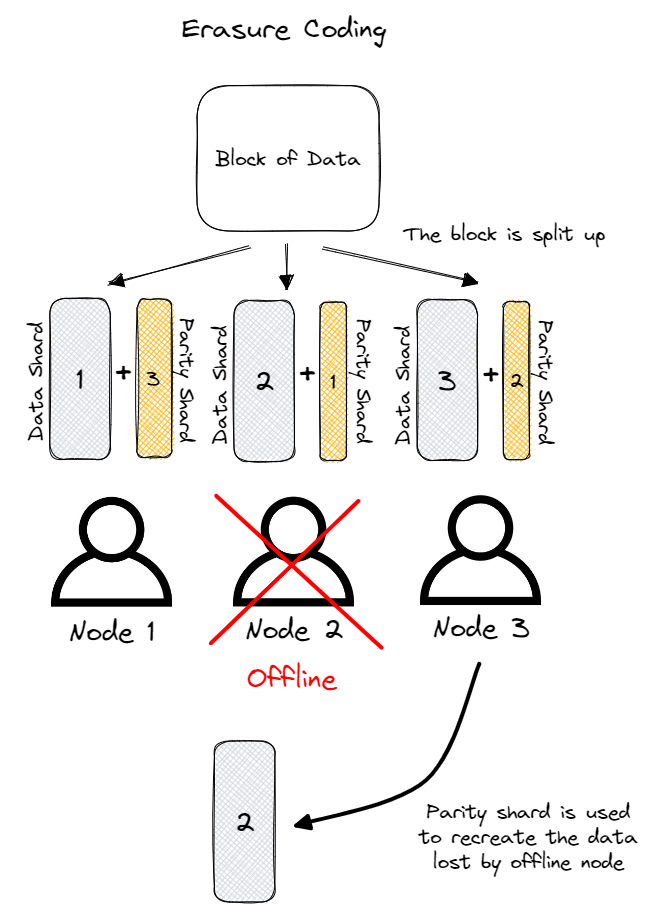
The process of erasure coding unveils its artistry by transforming the original data into a polynomial, its coefficients the key to the redundant data. Encoding symbols, or specific points, are chosen with care, ensuring the polynomial can be reconstructed from enough of these symbols even if some are lost or corrupted.
Reed-Solomon coding, a common erasure coding method, employs polynomial interpolation to create multiple encoded copies of the original data. Consider a message, “HELLO,” to be encoded. First, it’s converted into a sequence of numbers, such as ASCII codes: 72, 69, 76, 76, 79. Next, a polynomial is fashioned with these numbers as coefficients:
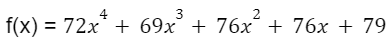
Finally, you evaluate the polynomial at several points to get the encoded message. For instance, if you evaluate the polynomial at 5 points, you would get 5 encoded copies of the message:
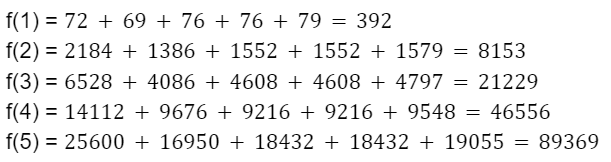
Accordingly, we have the following points along our polynomial: (1, 392), (2, 8153), (3, 21229), (4, 46556), (5, 89369). Now, suppose you lose 3 of these encoded copies, only retaining, for example, f(3) and f(5). You can still reconstruct the original message by using polynomial interpolation to find the original polynomial based on the remaining encoded copies.
Armed with the points (3, 21229) and (5, 89369), we turn to polynomial interpolation once more. Given that the polynomial has degree 4, a 4th degree polynomial that passes through these two points can be found:
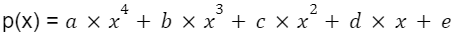
We substitute the points into the equation:
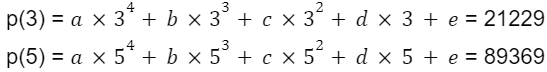
Solving for a, b, c, d, and e using a matrix inversion method, we find that:
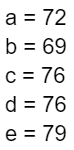
The polynomial equation glides through the points (3, 21229) and (5, 89369), mirroring the original equation:
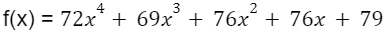
By evaluating the polynomial at x=0, we begin to unravel the original message:
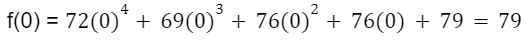
Since the polynomial “f(x)” is equivalent to the original message encoded using erasure coding, the value of the polynomial at x=0 gives us the last character of the message, “O”. To recover the full message “HELLO,” we must evaluate the polynomial at x=1, x=2, x=3, and x=4:
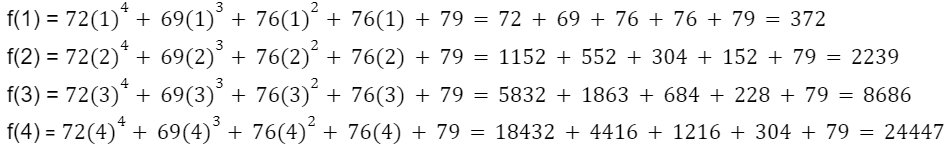
With these values, we can now convert the numerical results back into characters using their corresponding ASCII codes:
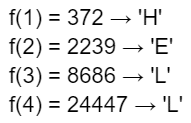
Assembling these letters, the original message is uncovered “HELLO”.
Data Availability Sampling (DAS)
The process of DAS is an innovative solution that addresses one of the key challenges in scaling blockchain systems: ensuring data availability without burdening nodes with the requirement to download and store the entire block. DAS relies on a constant number of samples to determine if the data is trustworthy and not being manipulated. The number of samples can be set to a specific value, such as 10, which results in approximately a 1 in 1000 chance of being tricked. Even with a higher number of samples, like 20, there is still only a 1 in a million chance of being tricked. The constant number of samples required does not change based on the size of the block, whether it is 1 megabyte, 1 gigabyte, or 1 terabyte. This is fundamentally hugely important to the scalability of Celestia’s approach as it means the number of samples required will remain constant regardless of block size.
However, this feature is not without limitations. In order to make the data secure, it cannot be arranged in a single line. Instead, it must be arranged in a square, extended in two dimensions. This means that commitments to storage are required for each row and column. The cost of this can be understood through asymptotic runtime and space complexity.
Asymptotic runtime and storage notation are used to describe the growth of algorithms with respect to the size of their inputs. In particular, O(n) is used to describe an algorithm whose runtime (or storage space) grows linearly with the size of the input. In other words, if the size of the input increases by a factor of 2, the runtime (or storage space) of the algorithm will also increase by a factor of 2.
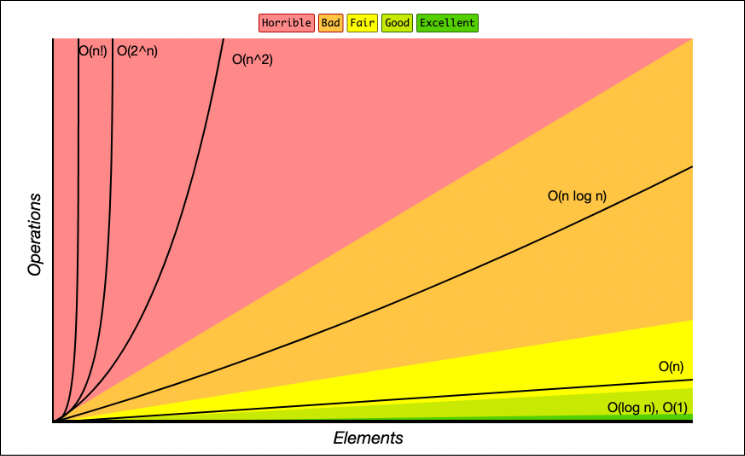
Source: freeCodeCamp
O(1) is used to describe an algorithm whose runtime (or storage space) remains constant regardless of the size of the input. This means that if the size of the input increases by a factor of 2, the runtime (or storage space) of the algorithm does not change. O(1) algorithms are considered to be very efficient because their runtime (or storage space) does not grow as the size of the input increases. Furthermore, O(√n) is used to describe an algorithm whose runtime (or storage space) grows at a rate slower than linear, specifically, proportional to the square root of the size of the input. This means that if the size of the input increases by a factor of 2, the runtime (or storage space) of the algorithm will increase by a factor of the square root of 2, which is approximately 1.41.
The benefit of O(√n) over O(n) storage space is that the former is more scalable than the latter. If an algorithm has O(n) storage space, the storage space required will grow linearly with the size of the input. This can quickly become infeasible if the size of the input is very large. On the other hand, if an algorithm has O(√n) storage space, the storage space required will grow at a much slower rate, proportional to the square root of the size of the input. This means that the algorithm will be able to handle larger inputs while still maintaining a manageable amount of storage space.
Light nodes can take advantage of this by downloading a small portion of the block, consisting of the commitments, proportional to the square root of the block size. After performing a constant number of samples, light nodes can determine if the block data is available or not, without having to download the entire block. Accordingly, this overcomes the data availability problem with trust-minimised light clients.
To prevent clients from needing to download the entire block data, negating the efficiency value proposition of DAS, two-dimensional erasure coding is used, limiting fraud proofs to a specific axis, as only one row or column needs to be downloaded to prove that the erasure code is incorrectly computed. Thus, the fraud-proof size would be approximately O(√n) (without Merkle proofs) for a block with n shares. However, this also requires clients who want data availability guarantees to download a Merkle root for the shares in each row and column as part of the block header, rather than a single Merkle root for the entire data. Consequently, the number of Merkle roots that need to be downloaded increases from 1 to 2√n, as there are √n rows and √n columns.
How Celestia Achieves Its Purpose
The system’s main objective is to enable clients to access all relevant messages associated with the application they are interested in, without the necessity to download the entire blockchain, ergo ensuring they can remain light clients. This feat is accomplished by querying storage nodes for all messages within a specific application namespace for particular blocks, while the storage node delivers Merkle proofs confirming the inclusion of relevant messages in those blocks.
Querying Storage Nodes
The first step towards efficient data retrieval involves clients querying storage nodes for all messages related to a specific application namespace within selected blocks. In response, the storage nodes provide Merkle proofs, acting as evidence for the inclusion of the relevant messages in the specified blocks.
Utilising Namespaced Merkle Trees
Central to Celestia’s data retrieval system is the employment of a namespaced Merkle tree, which is an ordered Merkle tree with a modified hash function. This distinctive function incorporates information regarding the range of namespaces for messages found in the descendants of each node within the tree. As a result, each non-leaf node contains data pertaining to the lowest and highest namespace identifiers among all descendant leaf nodes, as well as the hash resulting from concatenating the children of the node. Consequently, Merkle inclusion proofs can be generated to demonstrate the inclusion of all elements of the tree for a particular namespace.
The namespaced Merkle tree is constructed using standard Merkle tree algorithms. However, these algorithms are adapted to incorporate a hash algorithm that prefixes hashes with namespace identifiers. This tailored hash function, known as “nsHash,” takes into account the lowest and highest namespace identifiers present in the children of the node it represents.
Safeguarding Against Incorrectly Ordered Merkle Trees
To ensure the security and integrity of the system, the nsHash function includes a condition that prevents valid hashes when the left child’s maximum namespace is greater than or equal to the right child’s minimum namespace. This measure guarantees that any block containing an improperly constructed Merkle tree is deemed invalid.
Verifying Merkle Proofs
The final step in Celestia’s data retrieval process is the verification of Merkle proofs, which requires an extra step to confirm that the proofs cover all messages for a specific namespace. To accomplish this, a client node sends a query to a storage node, requesting all messages in a particular block linked to a certain namespace ID. In return, the storage node supplies a list of Merkle proofs, along with an index that specifies the first proof’s location within the tree.
The client node is then responsible for verifying that the proofs cover all messages for the specified namespace and that the namespaces are ordered correctly. If no messages are associated with the namespace ID, the storage node returns a single proof that corresponds to the child in the tree where the left child is smaller than the namespace ID and the right child is larger.
A Summary of the Problems Celestia is Conquering & How
Celestia is a cutting-edge blockchain technology, designed as a pluggable consensus and data availability layer for other blockchains, with a focus on rollups. It separates consensus and execution, using Cosmos’ Tendermint consensus protocol for consensus and ensuring data availability. Its main innovation is the division of transaction ordering and validation, with a thin core layer for ordering and the execution layer for validation, ergo enhancing efficiency.
Celestia’s architecture liberates rollups from dependency on other blockchains for execution, ensuring the shared history of ordered transactions. It acts as a “data availability oracle” that verifies data availability, maintaining security and functionality even with malicious block proposers. Data Availability Sampling (DAS) is a key feature in Celestia’s approach to achieving data availability while maintaining scalability.
DAS uses erasure coding, a redundancy technology, to ensure data recovery in cases of corruption or loss. Erasure coding uses polynomial interpolation to create multiple encoded copies of the original data, allowing recovery of the original message even with the loss of some encoded copies. Celestia’s DAS implementation enables blocks to be validated in sub-linear time due to widespread participation, leading to smaller fees and preventing network spamming.
DAS addresses the challenge of ensuring data availability without requiring nodes to download and store entire blocks. It relies on a constant number of samples to determine if the data is trustworthy. This approach is scalable, as the number of samples remains constant regardless of block size.
Celestia’s main objective is to enable clients to access relevant messages without downloading the entire blockchain. This is achieved by querying storage nodes for messages within specific application namespaces and having the storage nodes provide Merkle proofs confirming the inclusion of relevant messages in the blocks.
The Synergy Between Rollups and Celestia
Celestia’s architecture as a pluggable data availability and consensus layer seeks to enable developers to create their own chains without the burden of establishing their own validation network. As explained above, this is achieved through structuring blocks with a Merkle tree organised by the namespace of each transaction. This system allows users to query storage nodes in Celestia and request transactions specifically associated with their applications. In this way, users can interact with the Celestia chain solely for the rollups or applications they use, without downloading irrelevant transactions from other applications.
The subtle separation of namespaces enables a scalable and universal pluggable consensus layer. Each application can exist autonomously and be easily managed without the need for shared consensus. This stands in contrast to existing blockchain models, where the consensus and execution layers are tightly coupled, necessitating users to verify transactions across all smart contracts.
Rollups function as the execution layer by bundling multiple transactions into a single proof, thereby contributing to the network’s scalability. These proofs, along with the call data, are then posted onto Celestia. Celestia, in its role as the consensus layer, provides a secure and reliable platform for rollups. Its specialised namespace structure ensures that the data remains easily accessible and well-organised, further enhancing the efficiency of this collaboration.
The synergy between rollups and Celestia is evident in the way they work together. Rollups, as the execution layer, manage the flow of transactions and ensure efficiency within the network. Celestia, on the other hand, operates as the foundation for the rollups’ data management. By hosting the call data, Celestia ensures that users can access the information relevant to their applications with ease. Each layer specialises on a smaller set of purposes; in effect, when less thinly spread across various applications, the layers can offer cheaper fees and operate in a more scalable fashion.
The Future Applications of Celestia
Sovereign Rollups
Sovereign rollups on Celestia introduce a fresh perspective to the world of blockchain, serving as a layer 1 solution with a decentralised and trust-minimised foundation. Unlike relying on a smart contract, these rollups have their transactions ordered and verified directly on Celestia’s data availability layer, using Merkle proofs. The onus of verification and application of fork-choice rules falls on the rollup nodes, while the peer-to-peer network decides the canonical chain. Essentially, sovereign rollups embody a social agreement within the community, which sets transaction validity rules and permits chain upgrades via hard forks.
The distinct nature of sovereign rollups enables flexibility and self-sufficiency within the blockchain ecosystem. The lack of a bridge between the rollup and any settlement layer empowers the community to control transaction validity rules and deploy hard forks without external dependencies. Assets can be minted natively on the rollup chain, further emphasising the trust-minimised nature of this system.
Looking ahead, sovereign rollups have the potential to act as a catalyst for the emergence of settlement rollups, such as EclipseFND, that operate as a sovereign settlement layer for non-sovereign rollups. This innovative model showcases Celestia’s adaptability in the ever-changing blockchain landscape, highlighting its capacity to accommodate a wide range of execution layers while maintaining efficiency and scalability. In this dynamic environment, sovereign rollups can further solidify Celestia’s role as a pivotal force in the development of cutting-edge decentralised systems.
Hosting Additional Virtual Machines
Celestia distinguishes itself from other blockchains, like Ethereum and Solana, through its unique architecture that facilitates the hosting of multiple virtual machines. While Ethereum is limited to the EVM as the central tool to execute smart contracts, Celestia’s design does not enshrine any execution layer, allowing for sovereignty and shared security among the execution layers. This arrangement promotes efficient communication between roll-ups and affords flexibility as if running one’s own chain.
The potential of Celestia is further magnified by its ability to support experimentation with new virtual machines. Validators in Celestia are not tied to running any specific virtual machine, granting the execution layers the freedom to opt for any virtual machine they see fit. This unparalleled property opens the door for innovation in the virtual machine domain. For instance, it would enable developers to run a forked version of the EVM that omits the problematic self-destruct feature which destroys contracts and clears their storage or other features of this VM that certain developers perceive to be fundamental flaws.
Ethereum’s progress has been hindered by the cumbersome process of implementing changes to the EVM. Submitting a pull request (PR) to make changes to the EVM is time-consuming and often met with resistance from other developers, while hard-forking the Ethereum blockchain results in decreased security and the creation of an alternative L1 that may not be appealing to users. Celestia addresses this problem by offering a pluggable consensus and data availability layer; resultantly, developers can simultaneously run execution environments centred around modified EVM forks, leading to an expedited and less bounded rate of iteration. Smart contract developers can prioritise the changes they want to see implemented and vote with their feet by selecting the most suitable execution environment. This fosters a competitive market that propels innovation on the execution layer.

Celestiums
Celestiums function as layer 2 networks that depend on Ethereum for settlement and dispute resolution while using Celestia for data availability. They address the high costs faced by Ethereum rollups due to limited data capacity on Ethereum. In this architecture, the Quantum Gravity Bridge serves as a vital communication channel between the Celestia-based layer 2 and Ethereum, establishing a secure and consistent transfer of data.
Validators on Celestia attest to the transaction data by signing the Merkle root. This signed Merkle root is a compact representation of the entire transaction data set, allowing for efficient verification by the bridge contract on Ethereum. The bridge contract employs Merkle proofs to verify that the attested transaction data is genuine, ensuring the integrity of the data transfer between the two chains.
This process allows the layer 2 anchor contract on Ethereum to update its state based on the attested transaction data, leading to optimised data availability and ordering. Celestia’s Proof of Stake (PoS) consensus mechanism, combined with the large permissionless group of stakers, provides a robust security foundation for off-chain data availability.
In the context of trust-minimised bridges between L1 and L2 blockchains, Celestiums exhibit a unique advantage. Trust-minimised bridges can be secured by a single full node, as they rely on shared data availability guarantees and an ability to interpret each other’s validity proofs. While blockchains lack shared data availability and cannot form trust-minimised bridges, Celestiums leverage the data availability provided by Celestia to establish these bridges with Ethereum.

Ethereum has access to the rollups’ data and can execute their validity proofs on-chain. These validity proofs, such as zkSNARKs or zkSTARKs, enable the Ethereum network to verify the correctness of the layer 2 state transitions without needing to know the entire transaction history. Consequently, any single rollup node can secure the trust-minimised bridge between the layer 2 network and Ethereum.
Celestia facilitates the formation of clusters among chains without enforcing this arrangement. Chains built on Celestia have the flexibility to be standalone or create trusted or trust-minimised bridges with other chains. Notably, validity proofs can also be executed off-chain; they can be distributed through the peer-to-peer layer and executed client-side, reducing the need for on-chain computation and further increasing scalability.
Protecting Rollups from Distributed Denial of Service (DDoS) Attacks
Although Celestia does not execute transactions, it nevertheless does face the risk of rollups being spammed with invalid transactions. This concern arises from the potential inclusion of invalid transactions in a block or the threat of a DDoS attack on the chain. However, Celestia has implemented multiple strategies to mitigate these risks, ensuring the stability and security of rollups that post calldata on its chain.
One key method Celestia uses is posting entire rollup blocks rather than individual transactions. This approach significantly reduces the risk of transaction spam. Yet, the issue of invalid blocks still needs to be addressed. To tackle this challenge, Celestia serves as an alternative to traditional peer-to-peer distribution networks like those employed by Ethereum and Bitcoin. In this system, when a rollup full node receives an invalid block header, it downloads the block header and checks whether the appropriate number of validators or block producers from the rollup’s set have signed off on it. If the block is found to be entirely invalid, it can be discarded, and the processing of the subsequent block can commence.
Contrary to a prevalent misconception in the Ethereum community, rollups do not necessitate complete reliance on the block producer set for validity. Instead, rollups can employ mechanisms such as fraud proofs and data availability proofs, ensuring that the validity of blocks is not solely contingent upon block producers. This methodology enables the creation of trust-minimised light clients for rollups on Celestia. These light clients track raw block headers and ensure their availability without depending on the rollup’s block producers for block validity. By adopting these measures, Celestia is able to protect rollups from spam and DDoS attacks such that these layer 2s can be safely built atop the data availability layer it offers.
Cevmos: Settlement Layer for Rollups
Cevmos is an EVM sovereign settlement rollup that is designed to operate on top of Celestia and serve as a communication bridge between different rollups. The network comprises a three-layered architecture: Celestia, Evmos, and Rollups. Cevmos maintains EVM compatibility, meaning that smart contract developers can easily migrate their existing rollup smart contracts from Ethereum to Cevmos without any modifications. Cevmos is specifically tailored to handle settlement transactions between rollups and not general-purpose smart contracts, which are deployed on the third layer.
Underpinning Cevmos is Evmos, an EVM-compatible blockchain constructed on the Cosmos Network. It aims to facilitate seamless interoperability between the Ethereum and Cosmos ecosystems, fostering collaboration and cross-chain interactions. Utilising the Inter-Blockchain Communication (IBC) protocol, Evmos connects Ethereum-based applications with Cosmos’ modular, scalable infrastructure, rendering it highly critical in assisting Cevmos achieve its goals. Cevmos leverages the Evmos Hub via IBC and uses its native token, $EVMOS, for security and gas, resulting in a robust and efficient settlement layer for EVM rollups.
This EVM-compatible settlement layer restricts execution to rollup smart contracts and simple transfers between rollups. By doing so, it is prohibitively expensive for non-rollup networks to utilise the platform, ultimately enhancing its scalability compared to Ethereum. The proposed settlement layer, built using Celestia, Evmos, and Cosmos, functions as a modular stack for EVM-based applications. Its implementation as a Celestia rollup leverages the Optimint consensus engine instead of Tendermint, allowing developers to deploy new chains using an existing consensus and data availability layer.
With rollups deployed on top of the settlement rollup, developers can continue using the same contracts and software as those on Ethereum. The settlement rollup batches data using Optimint and posts it to Celestia, streamlining the redeployment of rollup contracts with minimal effort. To ensure a censorship-resistant block production leader selection mechanism, research is underway by several Ethereum rollup teams to decentralise block sequencers and prevent a single party from creating blocks that would require fraud-proof distribution at no cost.
Cevmos has been designed to serve as a specialised settlement chain on top of Celestia, allowing other execution chains to anchor to it within a single trust-minimised “cluster”. This configuration facilitates trust-minimised bridging between Celestia chains. Evidently, by optimising the features of Celestia and Evmos for rollups, Cevmos can provide Ethereum-native DApps with lower fees and better levels of scalability.
Conclusion
Modular scaling solutions are becoming a key approach for blockchain engineers to address challenges in traditional stack blockchains. Despite the efforts of many teams in this sector, it’s likely that other solutions will continue to be implemented, as is typical in decentralised industries and markets. Celestia, however, has made significant strides in utilising its technology across various aspects of the blockchain industry. By employing DAS to create a lightweight storage system, Celestia has enabled more validators to contribute to decentralising the network while simultaneously reducing gas costs for users of execution-focused networks. Currently, the effectiveness of Celestia is being put to the test as the industry starts to see networks that leverage Celestia’s consensus and data availability layer, marking an exciting phase in the evolution of blockchain technology.
About Zerocap
Zerocap provides digital asset liquidity and custodial services to forward-thinking investors and institutions globally. For frictionless access to digital assets with industry-leading security, contact our team at [email protected] or visit our website www.zerocap.com
FAQs
What is the main problem that Celestia aims to solve in the blockchain space?
Celestia addresses the issue of high gas fees and scalability in blockchain networks. It focuses on the data availability problem, which arises when developers aim to build trust-minimized light clients that have access to all data in a block. Celestia offers a modular alternative for light clients, reducing reliance on full nodes and enhancing scalability.
How does Celestia’s architecture differ from traditional blockchains?
Celestia’s key innovation lies in the separation of transaction ordering and validation. Instead of validating transactions, Celestia uses a thin core layer to order transactions, while the execution layer of the modular blockchain stack is responsible for validation. This reduces complexity and enhances the overall efficiency of the system.
What is Data Availability Sampling (DAS) and how does Celestia use it?
Data Availability Sampling (DAS) is a method that ensures data availability without requiring nodes to download and store the entire block. Celestia uses DAS to allow validators to perform smaller tasks, leading to smaller fees and preventing bots from spamming the network. The number of samples required remains constant regardless of block size, contributing to Celestia’s scalability.
What is erasure coding and how does it contribute to Celestia’s approach?
Erasure coding is a technique that adds redundant data to the original data, enabling recovery even in cases of corruption or loss. Celestia’s DAS implementation takes advantage of erasure coding, enabling blocks to be validated in sub-linear time due to widespread participation.
How does Celestia’s approach contribute to the future of blockchain technology?
By decoupling consensus and execution, Celestia paves the way for a more modular blockchain ecosystem. Various projects can leverage its data availability guarantees without being confined by a single execution environment. This framework offers a scalable and secure foundation for the future of blockchain technology, accommodating a wide array of applications and protocols that can seamlessly integrate with Celestia to achieve unparalleled levels of efficiency and security.
DISCLAIMER
Zerocap Pty Ltd carries out regulated and unregulated activities.
Spot crypto-asset services and products offered by Zerocap are not regulated by ASIC. Zerocap Pty Ltd is registered with AUSTRAC as a DCE (digital currency exchange) service provider (DCE100635539-001).
Regulated services and products include structured products (derivatives) and funds (managed investment schemes) are available to Wholesale Clients only as per Sections 761GA and 708(10) of the Corporations Act 2001 (Cth) (Sophisticated/Wholesale Client). To serve these products, Zerocap Pty Ltd is a Corporate Authorised Representative (CAR: 001289130) of AFSL 340799
All material in this website is intended for illustrative purposes and general information only. It does not constitute financial advice nor does it take into account your investment objectives, financial situation or particular needs. You should consider the information in light of your objectives, financial situation and needs before making any decision about whether to acquire or dispose of any digital asset. Investments in digital assets can be risky and you may lose your investment. Past performance is no indication of future performance.
Like this article? Share
 Share
Share  Tweet
Tweet  Post
Post 
Latest Insights
Weekly Crypto Market Wrap: 27 July 2026
Zerocap is a market-leading digital asset firm, providing trading, liquidity and custody to forward-thinking institutions and investors globally. To learn more, contact the team at
Weekly Crypto Market Wrap: 20 July 2026
Zerocap is a market-leading digital asset firm, providing trading, liquidity and custody to forward-thinking institutions and investors globally. To learn more, contact the team at
Weekly Crypto Market Wrap: 13 July 2026
Zerocap is a market-leading digital asset firm, providing trading, liquidity and custody to forward-thinking institutions and investors globally. To learn more, contact the team at
Receive Our Insights
Subscribe to receive our publications in newsletter format — the best way to stay informed about crypto asset market trends and topics.